Multi-Cloud Disaster Recovery — Automated AWS + Azure Failover with Route 53 Health Checks
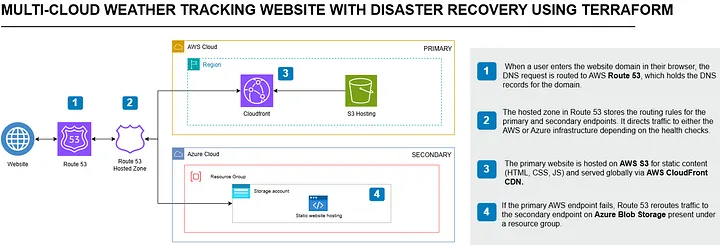
Full architecture: Route 53 health-check-based failover between AWS CloudFront + S3 (primary) and Azure Blob Storage (standby), provisioned from a single Terraform configuration
A working multi-cloud disaster recovery system that automatically fails over from AWS to Azure when the primary goes down — no manual intervention, no custom scripts, no third-party tools. Just Route 53 health checks, a failover routing policy, and a single Terraform configuration that deploys to both clouds simultaneously.
Stack
The Problem
Most static site hosting setups have a single point of failure: one cloud provider. If that provider has an outage — even a regional one — your site goes down and there is nothing you can do except wait. The standard DR advice is "use multiple regions," but that still leaves you dependent on a single cloud. A true DR system needs a second cloud entirely.
I wanted to build a system where AWS going down does not mean the site goes down.
What This System Does
The site runs on two clouds simultaneously. AWS S3 + CloudFront is the primary. Azure Blob Storage is the standby. Route 53 monitors both with health checks every 30 seconds. When the primary fails, Route 53 automatically starts returning the Azure endpoint. When AWS recovers, traffic returns automatically. No manual intervention at any step.
A single terraform apply provisions S3, CloudFront, Azure Blob Storage, and all DNS records simultaneously from one codebase.
Two HTTPS health checks ping the primary (CloudFront) and secondary (Azure Blob) every 30 seconds with a failure threshold of 3.
A primary A-record alias points to CloudFront. A secondary CNAME points to Azure. When the health check fails, Route 53 stops returning the primary record automatically.
With a 300-second TTL, the effective RTO is ~90 seconds detection time plus up to 5 minutes for cached resolvers to expire.
When the S3 bucket policy is restored and the health check passes again, Route 53 returns traffic to the primary CloudFront distribution without any manual action.
Building the System — 4 Phases
Phase 1 — AWS Primary: S3 + CloudFront
The primary hosting layer uses S3 for static website hosting with CloudFront as the CDN in front of it. The S3 bucket is configured with static website hosting enabled, public read access via a bucket policy, and lifecycle rules to prevent accidental deletion. CloudFront handles TLS termination using an ACM certificate for the custom domain, with HTTP-to-HTTPS redirection configured on the listener.
All website files — HTML, CSS, JavaScript, and image assets — are uploaded to S3 using Terraform's aws_s3_object resource with a for_each loop over the assets directory. Adding new files to the website only requires dropping them into the folder and running terraform apply.
Phase 2 — Azure Standby: Blob Storage Static Website
The standby site runs on Azure Blob Storage with the static website feature enabled. A resource group, storage account (StorageV2, LRS replication), and the $web container are provisioned via Terraform's azurerm provider. The same website files are uploaded to Azure using azurerm_storage_blob with a content-type lookup map that assigns the correct MIME type based on file extension.
The key design decision: both providers serve identical content from the same local source directory. One terraform apply deploys to both AWS and Azure simultaneously, eliminating any sync drift between primary and standby.
Phase 3 — DNS Failover with Route 53
Route 53 is the core of the DR mechanism. Two HTTPS health checks monitor the primary (CloudFront) and secondary (Azure Blob) endpoints, pinging every 30 seconds with a failure threshold of 3. The failover routing policy uses an A-record alias for the primary (pointing to the CloudFront distribution) and a CNAME for the secondary (pointing to the Azure Blob static website URL).
When the primary health check fails, Route 53 stops returning the CloudFront record and starts returning the Azure endpoint. DNS TTL is set to 300 seconds, so the effective RTO is the detection time (~90s) plus DNS propagation time (~5 minutes in the worst case for cached resolvers).
Phase 4 — Domain, TLS, and Verification
A custom domain was purchased from Namecheap (~$1) and the nameservers were pointed to Route 53's hosted zone. ACM provides the TLS certificate for CloudFront, validated via DNS. The entire DNS chain — domain registration → Route 53 hosted zone → health checks → failover records → CloudFront/Azure endpoints — was verified using DNS propagation checkers and manual failover testing.
Testing Failover
To validate the DR mechanism, I simulated an AWS outage by restricting the S3 bucket's public access policy, which causes CloudFront to return errors. Within ~90 seconds, Route 53's health check marked the primary as unhealthy and began resolving the domain to the Azure endpoint. The site remained functional throughout — users were served from Azure Blob Storage without any manual intervention.
Restoring the S3 bucket policy caused the health check to pass again, and traffic automatically returned to the primary CloudFront distribution.
Known Limitations and Production Path
Azure Blob Storage's static website feature does not natively support HTTPS with custom domains. In this setup, the Azure failover endpoint serves over HTTP, which produces a browser "Not secure" warning. In production, the fix is to place Azure CDN in front of the Blob Storage endpoint with a managed TLS certificate — the same pattern AWS uses with CloudFront + ACM.
This DR pattern works for static assets served from object storage. For dynamic applications with databases and server-side logic, the pattern would need to extend to include database replication (e.g., RDS cross-region read replicas or Cosmos DB multi-region writes) and compute failover (e.g., ECS/AKS with weighted routing).
The Hardest Problems I Solved
Running AWS and Azure providers in a single Terraform configuration requires careful credential isolation. I used separate .tfvars files for each provider and added *.tfvars to .gitignore to prevent credential leakage. The alternative — separate state files per provider — would have broken the single-apply deployment model that keeps both sides in sync.
Azure Blob Storage defaults all uploads to application/octet-stream if you don't set the content type explicitly. This breaks CSS and JS loading in the browser. Fixed with a lookup() map in Terraform that assigns the correct MIME type based on file extension for every uploaded asset.
Route 53 detects the outage in ~90 seconds, but DNS resolvers around the world cache records based on TTL. With a 300-second TTL, some users continued hitting the failed primary for up to 5 minutes after failover. In production, lowering the TTL to 60 seconds would reduce this window but increase DNS query costs — a trade-off worth documenting.
Key Takeaways
terraform apply provisions and deploys to both AWS and Azure simultaneously. The key is using separate provider blocks with isolated credentials and a shared source directory for the website files.